
Use Materialized Views
ClickHouse supports two types of materialized views: incremental and refreshable. While both are designed to accelerate queries by pre-computing and storing results, they differ significantly in how and when the underlying queries are executed, what workloads they are suited for, and how data freshness is handled.
Users should consider materialized views for specific query patterns which need to be accelerated, assuming previous best practices regarding type and primary key optimization have been performed.
Incremental materialized views are updated in real-time. As new data is inserted into the source table, ClickHouse automatically applies the materialized view's query to the new data block and writes the results to a separate target table. Over time, ClickHouse merges these partial results to produce a complete, up-to-date view. This approach is highly efficient because it shifts the computational cost to insert time and only processes new data. As a result, SELECT queries against the target table are fast and lightweight. Incremental views support all aggregation functions and scale well—even to petabytes of data—because each query operates on a small, recent subset of the dataset being inserted.

Refreshable materialized views, by contrast, are updated on a schedule. These views periodically re-execute their full query and overwrite the result in the target table. This is similar to materialized views in traditional OLTP databases like Postgres.
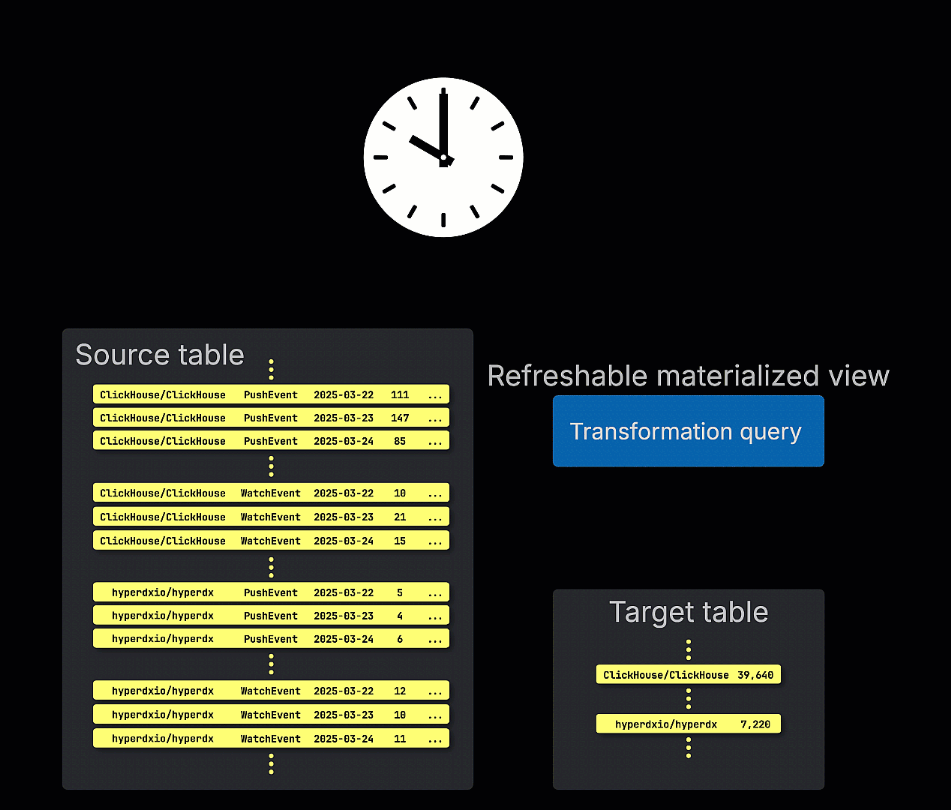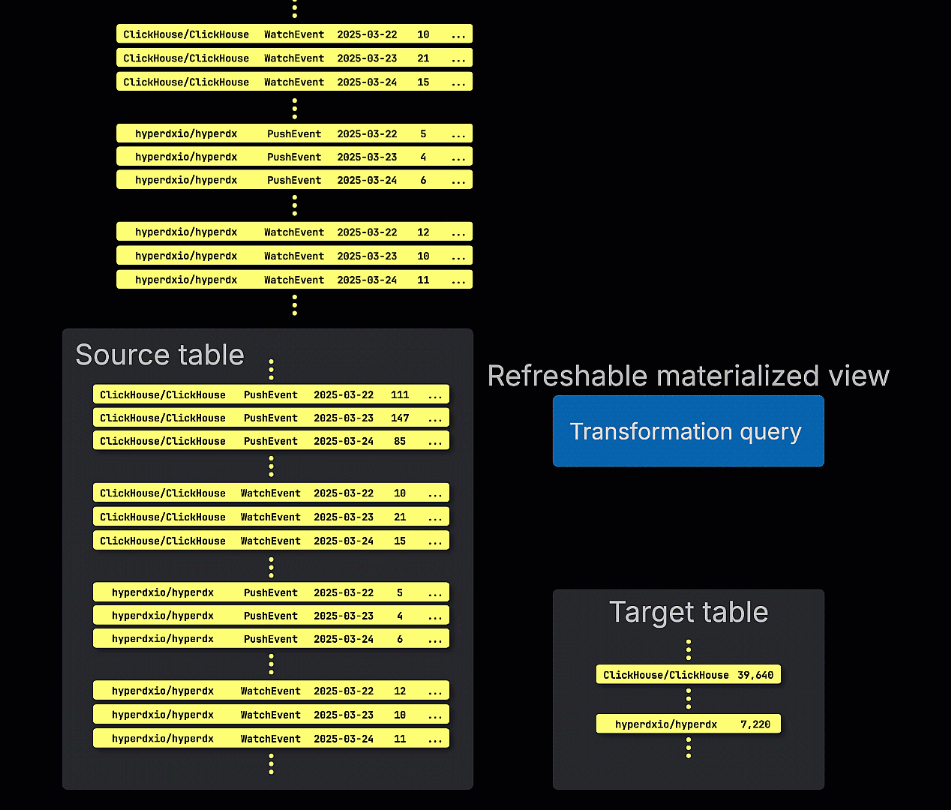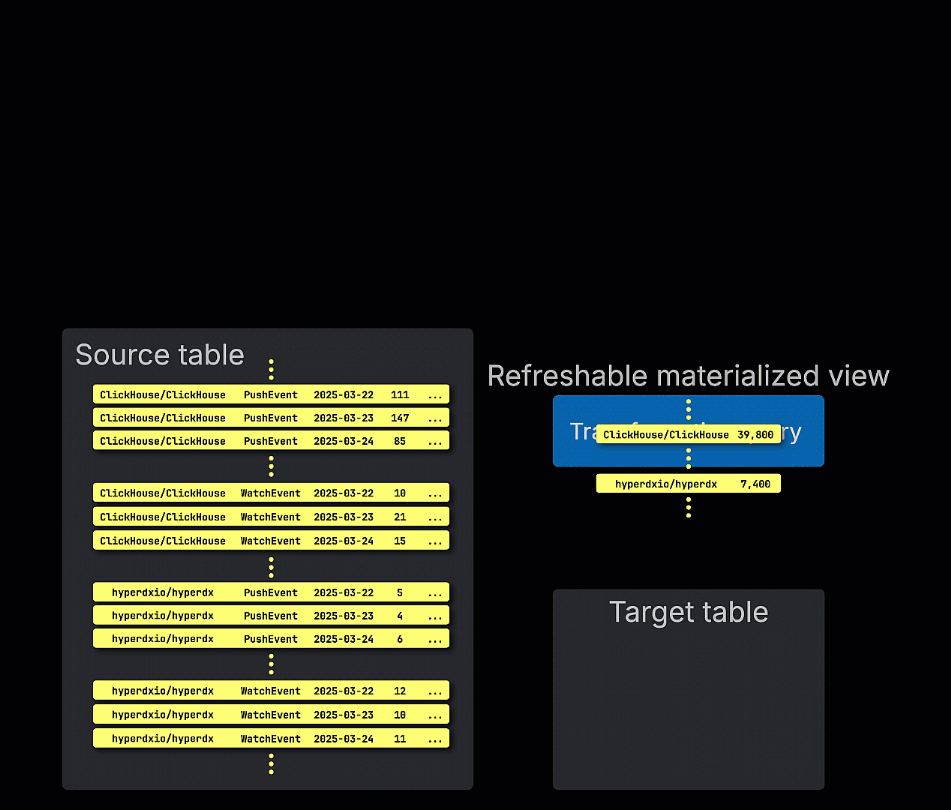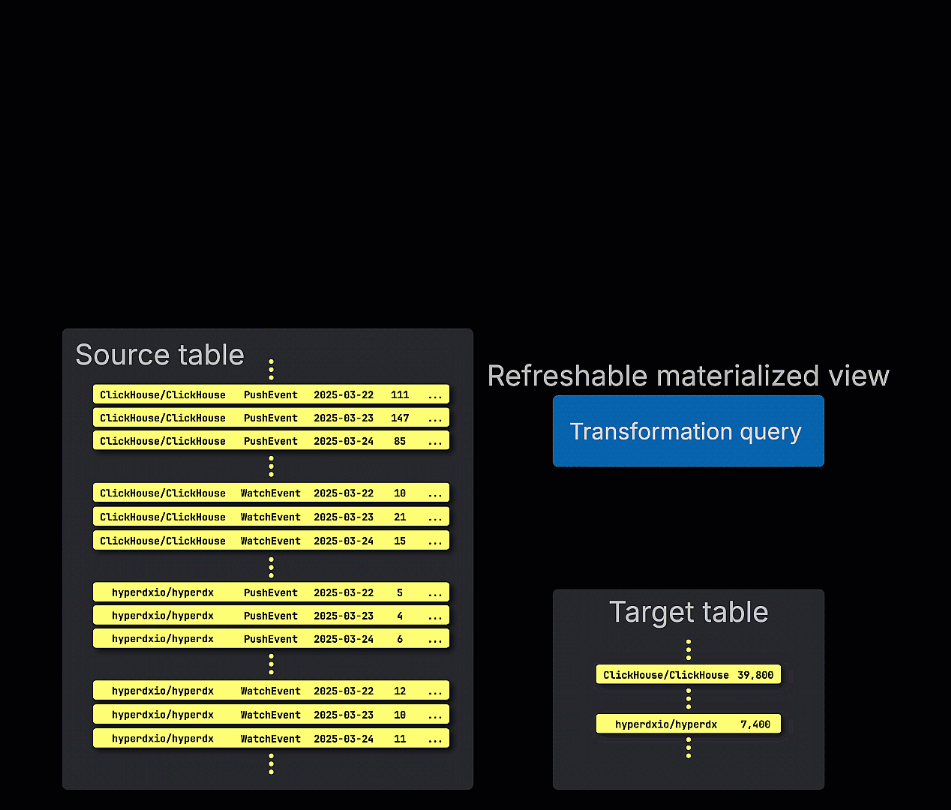
The choice between incremental and refreshable materialized views depends largely on the nature of the query, how frequently data changes, and whether updates to the view must reflect every row as it is inserted, or if a periodic refresh is acceptable. Understanding these trade-offs is key to designing performant, scalable materialized views in ClickHouse.
When to Use Incremental Materialized Views
Incremental materialized views are generally preferred, as they update automatically in real-time whenever the source tables receive new data. They support all aggregation functions and are particularly effective for aggregations over a single table. By computing results incrementally at insert-time, queries run against significantly smaller data subsets, allowing these views to scale effortlessly even to petabytes of data. In most cases they will have no appreciable impact on overall cluster performance.
Use incremental materialized views when:
- You require real-time query results updated with every insert.
- You're aggregating or filtering large volumes of data frequently.
- Your queries involve straightforward transformations or aggregations on single tables.
For examples of incremental materialized views see here.
When to Use Refreshable Materialized Views
Refreshable materialized views execute their queries periodically rather than incrementally, storing the query result set for rapid retrieval.
They are most useful when query performance is critical (e.g. sub-millisecond latency) and slightly stale results are acceptable. Since the query is re-run in full, refreshable views are best suited to queries that are either relatively fast to compute or which can be computed at infrequent intervals (e.g. hourly), such as caching “top N” results or lookup tables.
Execution frequency should be tuned carefully to avoid excessive load on the system. Extremely complex queries which consume significant resources should be scheduled cautiously - these can cause overall cluster performance to degrade by impacting caches and consuming CPU and memory. The query should run relatively quickly compared to the refresh interval to avoid overloading your cluster. For example, do not schedule a view to be updated every 10 seconds if the query itself takes at least 10 seconds to compute.
Summary
In summary, use refreshable materialized views when:
- You need cached query results available instantly, and minor delays in freshness are acceptable.
- You need the top N for a query result set.
- The size of the result set does not grow unbounded over time. This will cause performance of the target view to degrade.
- You're performing complex joins or denormalization involving multiple tables, requiring updates whenever any source table changes.
- You're building batch workflows, denormalization tasks, or creating view dependencies similar to DBT DAGs.
For examples of refreshable materialized views see here.
APPEND vs REPLACE Mode
Refreshable materialized views support two modes for writing data to the target table: APPEND and REPLACE. These modes define how the result of the view's query is written when the view is refreshed.
REPLACE is the default behavior. Each time the view is refreshed, the previous contents of the target table are completely overwritten with the latest query result. This is suitable for use cases where the view should always reflect the latest state, such as caching a result set.
APPEND, by contrast, allows new rows to be added to the end of the target table instead of replacing its contents. This enables additional use cases, such as capturing periodic snapshots. APPEND is particularly useful when each refresh represents a distinct point-in-time or when historical accumulation of results is desired.
Choose APPEND mode when:
- You want to keep a history of past refreshes.
- You're building periodic snapshots or reports.
- You need to incrementally collect refreshed results over time.
Choose REPLACE mode when:
- You only need the most recent result.
- Stale data should be discarded entirely.
- The view represents a current state or lookup.
Users can find an application of the APPEND functionality if building a Medallion architecture.