
Choosing a Partitioning Key
Partitioning is primarily a data management technique and not a query optimization tool, and while it can improve performance in specific workloads, it should not be the first mechanism used to accelerate queries; the partitioning key must be chosen carefully, with a clear understanding of its implications, and only applied when it aligns with data life cycle needs or well-understood access patterns.
In ClickHouse, partitioning organizes data into logical segments based on a specified key. This is defined using the PARTITION BY clause at table creation time and is commonly used to group rows by time intervals, categories, or other business-relevant dimensions. Each unique value of the partitioning expression forms its own physical partition on disk, and ClickHouse stores data in separate parts for each of these values. Partitioning improves data management, simplifies retention policies, and can help with certain query patterns.
For example, consider the following UK price paid dataset table with a partitioning key of toStartOfMonth(date).
Whenever a set of rows is inserted into the table, instead of creating (at least) one single data part containing all the inserted rows (as described here), ClickHouse creates one new data part for each unique partition key value among the inserted rows:
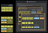
The ClickHouse server first splits the rows from the example insert with 4 rows sketched in the diagram above by their partition key value toStartOfMonth(date). Then, for each identified partition, the rows are processed as usual by performing several sequential steps (① Sorting, ② Splitting into columns, ③ Compression, ④ Writing to Disk).
For a more detailed explanation of partitioning, we recommend this guide.
With partitioning enabled, ClickHouse only merges data parts within, but not across partitions. We sketch that for our example table from above:

Applications of partitioning
Partitioning is a powerful tool for managing large datasets in ClickHouse, especially in observability and analytics use cases. It enables efficient data life cycle operations by allowing entire partitions, often aligned with time or business logic, to be dropped, moved, or archived in a single metadata operation. This is significantly faster and less resource-intensive than row-level delete or copy operations. Partitioning also integrates cleanly with ClickHouse features like TTL and tiered storage, making it possible to implement retention policies or hot/cold storage strategies without custom orchestration. For example, recent data can be kept on fast SSD-backed storage, while older partitions are automatically moved to cheaper object storage.
While partitioning can improve query performance for some workloads, it can also negatively impact response time.
If the partitioning key is not in the primary key and you are filtering by it, users may see an improvement in query performance with partitioning. See here for an example.
Conversely, if queries need to query across partitions performance may be negatively impacted due to a higher number of total parts. For this reason, users should understand their access patterns before considering partitioning a a query optimization technique.
In summary, users should primarily think of partitioning as a data management technique. For an example of managing data, see "Managing Data" from the observability use-case guide and "What are table partitions used for?" from Core Concepts - Table partitions.
Choose a low cardinality partitioning key
Importantly, a higher number of parts will negatively affect query performance. ClickHouse will therefore respond to inserts with a “too many parts” error if the number of parts exceeds specified limits either in total or per partition.
Choosing the right cardinality for the partitioning key is critical. A high-cardinality partitioning key - where the number of distinct partition values is large - can lead to a proliferation of data parts. Since ClickHouse does not merge parts across partitions, too many partitions will result in too many unmerged parts, eventually triggering the “Too many parts” error. Merges are essential for reducing storage fragmentation and optimizing query speed, but with high-cardinality partitions, that merge potential is lost.
By contrast, a low-cardinality partitioning key—with fewer than 100 - 1,000 distinct values - is usually optimal. It enables efficient part merging, keeps metadata overhead low, and avoids excessive object creation in storage. In addition, ClickHouse automatically builds MinMax indexes on partition columns, which can significantly speed up queries that filter on those columns. For example, filtering by month when the table is partitioned by toStartOfMonth(date) allows the engine to skip irrelevant partitions and their parts entirely.
While partitioning can improve performance in some query patterns, it's primarily a data management feature. In many cases, querying across all partitions can be slower than using a non-partitioned table due to increased data fragmentation and more parts being scanned. Use partitioning judiciously, and always ensure that the chosen key is low-cardinality and aligns with your data life cycle policies (e.g., retention via TTL). If you're unsure whether partitioning is necessary, you may want to start without it and optimize later based on observed access patterns.